Répliquer avec Pgpool
INTRODUCTION
Notre but aujourd’hui est de nous approcher de la notion de cluster postgresql en haute disponibilité.
Certaines infrastructures critiques nécessitent de la haute disponibilité. La base de données est un point critique de toute application web. Pour garantir une qualité de service à vos utilisateurs il peut être intéressant de mettre en place un cluster de bases de données.
Nous allons nous intéresser plus précisément à la mise en place d’une haute disponibilité pour PostgreSQL en utilisant l’outil Pgpool II.
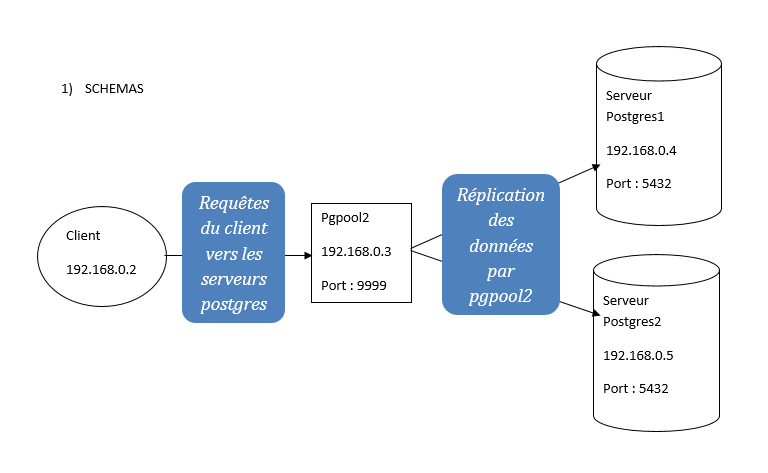
Pgpool est une application qui se place entre notre accès et PostgreSQL. Il permet notamment de faire la liaison entre les différentes instances de PostgreSQL, tout en permettant de mettre en place de la réplication, de la haute disponibilité et du load balancing.
Pgpool fonctionne par le principe de duplication de requêtes pour gérer la réplication. Chaque écriture sur PostgreSQL sera effectuée sur chaque serveur PostgreSQL du cluster.
Une fois la réplication et load balancing mis en place, certaines requêtes SELECT seront réparties entre les différents serveurs PostgreSQL. Voir la documention Pgpool pour connaître les conditions de requêtes en mode load balancing.
NB : Pgpool gère nativement la haute disponibilité avec Watchdog. Il nous permet de mettre en place une ip virtuelle, c’est à dire que les deux instances Pgpool vont se partager une ip unique qui pointera sur le Pgpool ayant le status master. Si le master n’est plus disponible, le serveur en standby va prendre la place du master et prendre aussi l’ip virtuelle. Le but de cette ip virtuelle est d’avoir un seul et même point d’entrée dans le cluster.
Nous pourrions également avoir une seule instance Pgpool, mais dans ce cas-ci nous nous exposons à un single point of failure, car il n’y a aucune redondance de Pgpool.
Dans cet exemple nous allons prendre le cas de deux serveurs hébergeant chacun un serveur PostgreSQL. Nous allons pour cela répliquer les données sur les deux serveurs, activer le load balancing et mettre en place la haute disponibilité.
Le but de cette architecture est de pouvoir avoir accéder à nos données même si l’un des deux serveurs n’est plus accessible. Cette architecture est extensible car nous pouvons rajouter autant de serveurs que nous voulons à notre cluster.
Voici les différents points que nous allons aborder dans cet article :
- Illustration de l’architecture finale
-
- Réplication
- Haute disponibilité
- SCHEMAS
2) MISE EN PLACE
A-) Installation des Paquets
- Installer Postgres sur les deux serveurs.
- Installer les package suivant :
. apt-get install libpq-dev postgresql-serveur-dev-9.5 bison
. apt-get install postgresql-contrib-9.1 postgresql-doc-9.5 uuid libdbd-pg-perl
. apt-install pgpool2 libpgpool0 (libpgpool“zéro”)
B-) Configuration de postgresql
- Configuration de pg_hba.conf
# Database administrative login by Unix domain socket
local all postgres trust
# TYPE DATABASE USER ADDRESS METHOD
# « local » is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
host all all 0.0.0.0/0 trust
# IPv6 local connections:
host all all ::1/128 trust
host all all 0.0.0.0/0 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
#local replication postgres peer
#host replication postgres 127.0.0.1/32 md5
#host replication postgres ::1/128 md5
host replication all 0.0.0.0/0 trust
- Configuration du fichier postgresql.conf
listen_addresses = ‘*’ # accepter toutes les connexions entrantes
wal_level = hot_standby # mode permettant de passer Postgres en master avec des noeuds en standby
max_wal_senders = 2
wal_keep_segments = 50
hot_standby = on
archive_mode = on
- Ensuite on redémarre les service de postgresql ( /etc/init.d/postgresql-9.5 restart )
NB : cette configuration est effectuée sur les deux serveurs postgres.
C-) CONFIGURATION DE Pgpool
- Se connecter en tant que root et éditer le fichier pgpool.conf ( gedit /etc/pgpool2/pgpool.conf)
Connection Serveur1 :
Listing addres = ‘* ‘
Port = 9999
Backend_hostname0 = ‘ adresse ip serveur1’
Backend_port0 = ‘port de postgres sur le serveur1 (5432)’
Backend_weight0 = 1
….
….
Backend_hostname1 = ‘ adresse ip serveur2’
Backend_port0 = ‘port de postgres sur le serveur2 (5432)’
Backend_weight1 = 1
…..
…..
Replication_mode = true
…
…
Load_balance_mode = true
…
…
- Puis on enregistre les modifications et on redémarre les services de pgpool2
- Puis on saisit cette commande en tant que root: –# pgpool -n -n -f /etc/pgpool2/pgpool.conf
- Ensuite on arrête les service de pgpool ; puis on saisit cette commande
- –# pgpool -n -d -f /etc/pgpool2/pgpool.conf et on laisse (on ne touche rien) la configuration est terminée sur pgpool
D-) Test du client
Sur son terminal en tant que root :
–# createdb -h 192.168.0.4 -p 9999 -U postgres -d bdtest
La base de données bdtest sera créer sur les deux serveur postgres.
NB : la machine cliente doit avoir le client postgres installer (apt-get install postgresql-client-9.5).
CONCLUSION
Malgré les différents problèmes qu’a pgpool il est néant moins efficace. Pour remédier à un problème sur un des serveurs il faut résoudre son problème et basculer le second en maitre sur pgpool et redémarrer pgpool. Apres remise à jour du serveur en panne on doit le restaurer avec les données du serveur à partir du client pour que pgpool puisse le revoir comme une nouvelle base de données.